LightLLM v1.0.0--Minimal Inter-Process Communication Overhead, Fastest DeepSeek-R1 Serving Performance on Single H200, and Prototype Support for PD-Disaggregation
By MTC Team ·We are delighted to announce the release of LightLLM v1.0.0. After a year of continuous efforts, we have comprehensively upgraded the LightLLM architecture. We have implemented a cross-process accessible request object, significantly reducing inter-process communication overhead, especially in high-concurrency scenarios. Meanwhile, we have conducted in-depth optimization for DeepSeek R1, achieving state-of-the-art performance among current open-source frameworks on a single H200 machine. Furthermore, we have innovatively proposed a prototype architecture implementation of PD-separation.
Framework
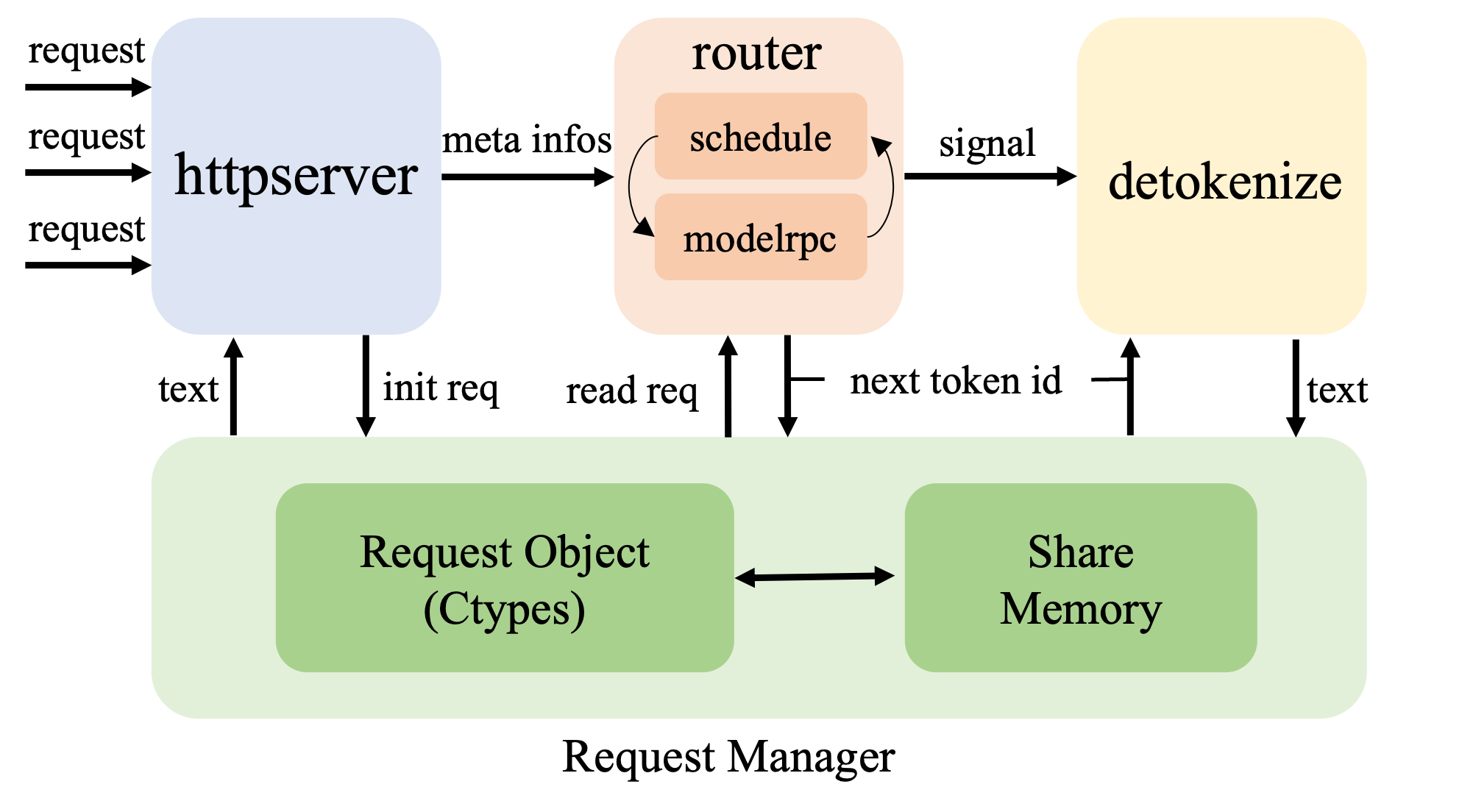
The new framework of LightLLM is shown in the figure below. We have retained the previous three-process architecture design and designed a request object that can be accessed across processes via ctypes. We store the metadata of the requests in shared memory, ensuring that only a minimal amount of necessary data is communicated between processes. Additionally, we have implemented the folding of scheduling and model inference, and have nearly eliminated the communication overhead between the scheduler and model-rpc in the previous version of the router. We implemented the CacheTensorManager class, which takes over the allocation and release of Torch tensors within the framework. This maximizes the cross-layer sharing of tensors at runtime, as well as memory sharing between different CUDA graphs. On an 8x80GB H100 machine, with the DeepSeek-v2 model, LightLLM can run 200 CUDA graphs concurrently without running out of memory (OOM). We will subsequently publish a series of blog posts introducing the architecture of LightLLM.
PD-Disaggregation Prototype
We have completed the prototype design of PD separation. For details, please refer to https://github.com/ModelTC/lightllm/tree/main/lightllm. We will subsequently provide a detailed structural explanation and performance data.
Optimization on DeepSeek
Due to the different computational characteristics of Prefill (compute intensive) and Decode (memory intensive), we have implemented distinct optimizations for the DeepSeek MLA. During the Prefill stage, we decompress the KV cache, while in the Decode stage, we compress the query (q) to achieve optimal performance. Additionally, we leveraged OpenAI’s Triton to implement high-performance Decode MLA and fused MoE kernels.
Performance
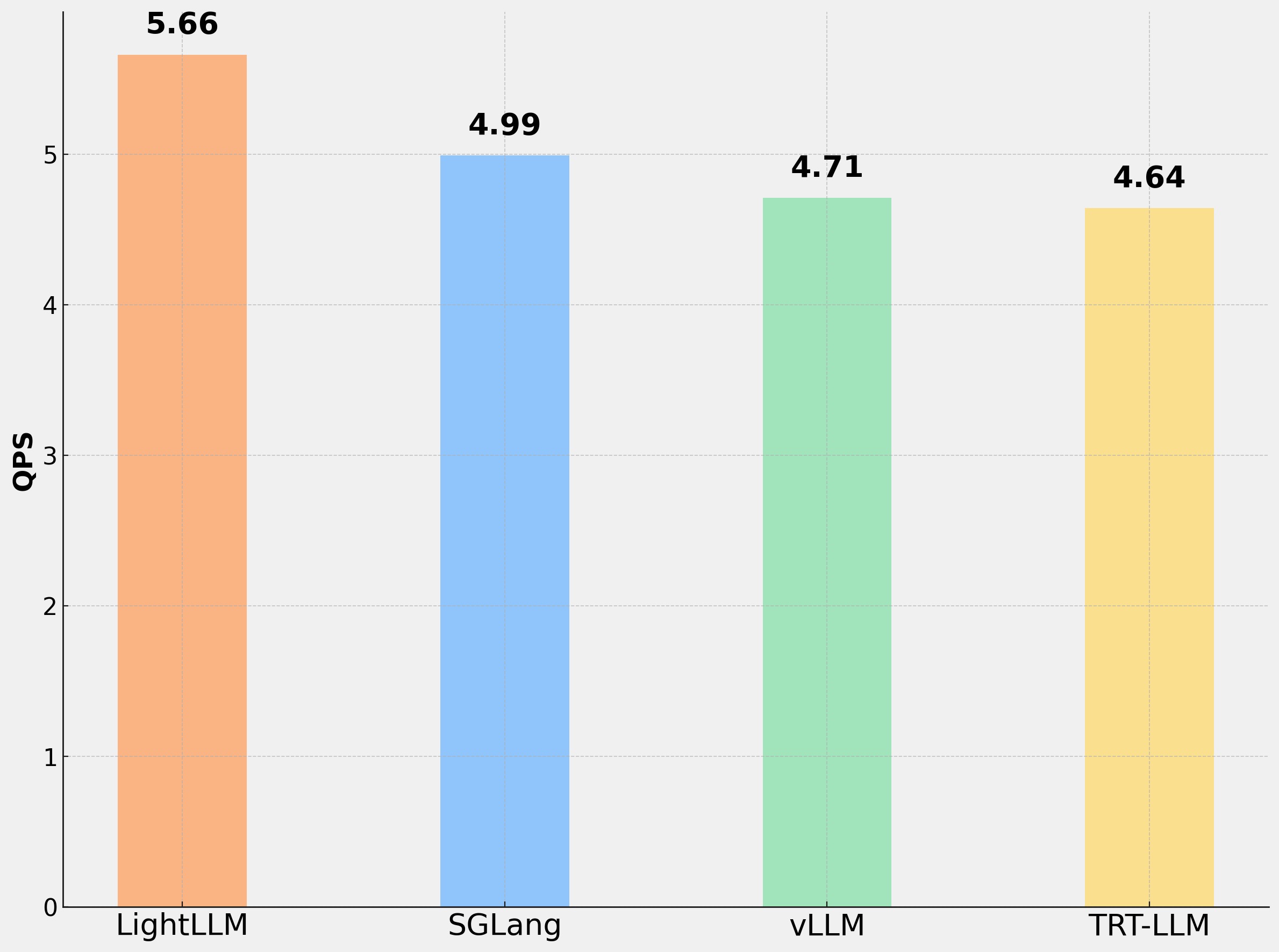
The figure below shows the performance comparison of LightLLM, sglang==0.4.3, vllm==0.7.2, and trtllm==0.17.0 on a single H200 machine, using DeepSeek-R1 (num_clients = 100). The input length of the test data is 1024, and the output follows a Gaussian distribution with a mean of 128. LightLLM achieves better performance.
Acknowledgment
We learned a lot from the following projects when developing LightLLM, including vLLM, sglang, and OpenAI Triton. We also warmly welcome the open-source community to help improve LightLLM.