Overview
In distributed parallel (DP) deployments, inefficient KV cache sharing leads to substantial redundant computations. This post introduces our solution: a prefix KV cache transfer mechanism that dramatically improves cache hit rates and reduces time to first token.
Problem Statement
In data parallel (DP) deployments, each dp_rank maintains its own independent radix_cache. This architecture creates a critical inefficiency: when multiple DP ranks are deployed, the cache hit probability decreases proportionally.
Consider a concrete example: deploying DeepSeek-R1 using DP+EP on an H200 single-node setup creates 8 DP ranks. In this configuration, the cache hit probability drops to merely 1/8 (12.5%), meaning 87.5% of hit requests perform redundant KV cache computations that could have been avoided.
This inefficiency becomes increasingly problematic as the number of DP ranks grows, wasting valuable compute resources on duplicate work.
Solution: Inter-Rank KV Cache Transfer
To eliminate this redundancy, we implemented a prefix KV cache transfer mechanism that enables DP rankers to share and reuse KV cache data across ranks.
Implementation Details
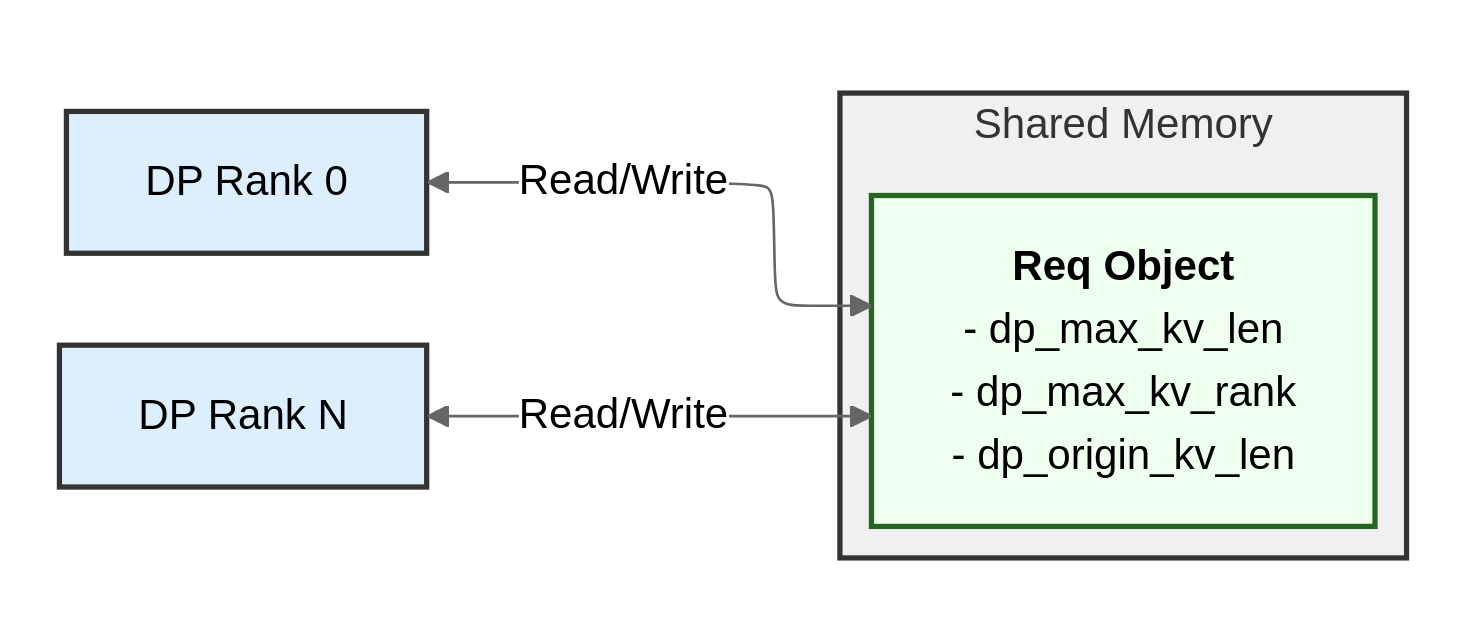
1. Request Metadata Tracking
We augmented the Req object with three new attributes to coordinate cache sharing:
dp_max_kv_len: The maximum prefix match length across all DP ranks for this requestdp_max_kv_rank: The DP rank ID that holds the longest matching prefixdp_origin_kv_len: The prefix match length on the current DP rank
Since Req is already implemented using shared memory, all DP ranks can access and update these fields. During request initialization, each DP rank iterates through all requests to populate these values.
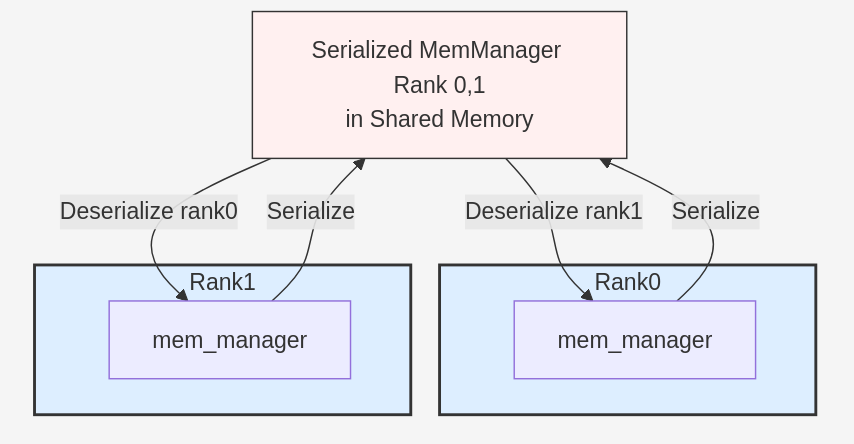
2. Memory Manager Serialization
Each DP rank serializes its mem_manager and stores it in shared memory, making it accessible to other ranks. However, we encountered a critical challenge during deserialization:
When deserializing torch.tensor objects, PyTorch’s C++ implementation switches the current CUDA device to the tensor’s storage_device before performing operations. This behavior causes pointer context mismatches when using Triton kernels, as the pointers become invalid in the process’s current device context.
Solution: We modified the tensor rebuild function by introducing p2p_fix_rebuild_cuda_tensor, which explicitly sets storage_device = torch.cuda.current_device(). This ensures that the subsequent kv_trans_for_dp kernel can safely access data across multiple GPU devices simultaneously.
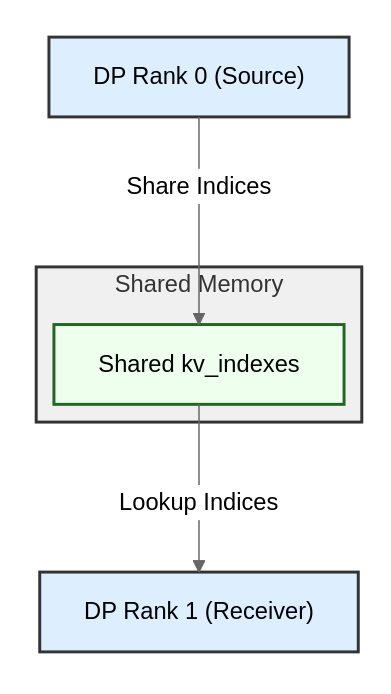
3. KV Index Sharing
Each DP rank identifies which requests require KV cache transfer to other ranks based on the three Req metadata fields. The corresponding kv_indexes for these requests are shared via shared memory, enabling efficient lookup by receiving ranks.
4. Cache Transfer Execution
For each request requiring cache data from another rank, the receiving DP rank:
- Identifies the source rank using
dp_max_kv_rank - Allocates storage indexes in its own
mem_managerfor the incoming KV cache - Executes the
kv_trans_for_dpkernel, which reads KV cache data from the source rank’smem_manager.kv_bufferusing the sharedkv_indexesand writes it to the localmem_manager.kv_buffer
This approach enables zero-copy, direct GPU-to-GPU memory access across ranks, minimizing transfer overhead.

Performance Evaluation
Test Configuration
We evaluated the system using the following benchmark:
python test/benchmark/service/benchmark_sharegpt.py \
--use_openai_api \
--dataset ./ShareGPT_V3_unfiltered_cleaned_split.json \
--tokenizer /data/DeepSeek-R1 \
--num-prompts 500 \
--concurrency 32 \
--history-turns 20
To properly assess KV cache benefits, we ran the benchmark twice consecutively. The second run demonstrates the impact of cache warming and cross-rank sharing.
Results
The performance improvements are substantial, particularly in the second run where cache reuse is maximized:
| Metric | First Run (Baseline) | First Run (With Transfer) | Second Run (Baseline) | Second Run (With Transfer) |
|---|---|---|---|---|
| Total Tokens | 759,336 | 759,336 | 759,336 | 759,336 |
| Total Time | 118.23 s | 119.16 s | 118.46 s | 115.16 s |
| Throughput (QPS) | 4.23 | 4.20 | 4.22 | 4.34 |
| Average Latency | 7.43 s | 7.49 s | 7.44 s | 7.23 s |
| Average Time to First Token | 0.41 s | 0.41 s | 0.41 s | 0.34 s |
| Average Latency per Token | 5.1 ms | 5.2 ms | 5.1 ms | 5.0 ms |
| Average Inter-token Latency | 69.3 ms | 69.8 ms | 69.3 ms | 68.0 ms |
Key Findings
- Time to First Token: Reduced by 0.07 seconds (17.1% improvement) in the cache-warmed second run
The first run shows minimal overhead from the transfer mechanism itself (<1%), while the second run demonstrates significant gains from effective cache sharing across DP ranks.
Conclusion
The prefix KV cache transfer mechanism effectively addresses the cache hit rate problem in multi-rank DP deployments. By enabling ranks to share cached prefixes, we reduce redundant computations and achieve measurable improvements in latency and throughput, particularly for workloads with repeated prefixes.
The 17% reduction in time to first token is especially valuable for interactive applications where user-perceived latency is critical. As DP rank counts increase, the benefits of this approach become even more pronounced.